工業大數據分析技術在實踐應用中的思路與方法(下篇)
2020-11-10 14:10:30
次
導讀:欲避免數據分析工作的陷阱,就須事先了解可能遇到的各類問題和困難。在《工業大數據分析技術在實踐應用中的思路和方法》(上篇)中,我們一起研討了工業大數據分析的特殊性和難點;今天我們將繼續和您分享(下篇)內容,共同探討如何用少的時間代價換取數據分析工作的高成功率和大價值;如何選擇合適的方法解決具體的應用問題,并對分析結果的可靠性做出科學評估,避免技術在具體應用中受阻、被淹沒……
一、工業大數據分析的基本框架
目前,業界在開展工業大數據分析時主要遵從CRISP-DM分析流程,以數據為中心,將相關工作分成業務理解、數據理解、數據準備、建模、驗證與評估、實施與運行等六個步驟,如下圖所示。此流程相關步驟存在多處循環和反復迭代,如業務理解和數據理解、數據準備和建模之間,整個分析過程需要在不斷交替中深入進行,甚至會出現模型驗證評估和業務理解之間的修正調整。
圖 1:CRISP-DM方法
由于工業數據關聯關系復雜、工業數據質量差、工業場景的分析要求高等導致CRISP-DM方法在工業領域的具體應用中遇到一些問題。加之,工業大數據分析過程中往往需要對業務和數據進行充分解讀,難免會出現大量無效的循環往復的工作,導致在用CRISP-DM方法分析時效率較低。所以,在工業大數據分析過程中,用好CRISP-DM的關鍵是減少上下步驟之間的反復,避免單向箭頭變成雙向。更需要注意的是,要盡量減少模型驗證評估失敗后重新進入業務理解這樣大跳躍的反復。這就是在前文提到的在開展工業大數據建模前要固化好分析場景和評估確定好數據條件。
二、工業大數據分析具體如何開展
長期實踐來看,CRISP-DM模型須補充進新內涵才能更好的指導工業應用場景的工業大數據分析。CRISP-DM模型在工業大數據的中的應用推進,主要分以下幾個階段:
01 業務理解
明確業務需求和數據分析的目標。
業務理解的過程通常需要將專業領域的知識和數據模型充分融合,業務領域的知識可作為工業建模的輸入變量融入到工業分析模型中,也可以作為知識去輔助建立高效地診斷、檢測、預測模型從而指導工業應用。工業大數據分析需要數據分析師深入理解業務,且要對這個“度”把握和控制好。一方面,只有數據分析師深入理解業務,才能實現領域知識與數據分析的有機融合,得到高水平、有價值的分析結果;另一方面,成為一個業務領域專家需要多年的積累,完整掌握業務知識是不現實的,需要專業人員及環境的多項支持。因此,為提升工業應用現場業務認知深度,企業基本是采用業務咨詢顧問和數據分析師配合組隊的模式來開展工業大數據分析工作。
02 數據理解
準確建立數據和業務間的關聯關系,從數據的角度深度解讀業務。
數據分析師會習慣性地把工業大數據分析過程中遇到的分析效率低、數據信噪比低、機理融合難、錯誤結果多等問題歸結到數據質量層面,而忽略在數據理解階段的深層次問題,而數據理解恰恰是數據建模的關鍵所在,也常常是數據分析過程中大家的盲點所在。數據理解需要從數據類型狀態、數據質量條件和數據間的關聯關系等方面開展判斷論證,確定是否滿足業務場景的要求。
03 數據準備
為工業建模分析提供干凈、有效的輸入數據源。
工業企業數據準備環節主要為解決業務應用問題開展數據集成治理,實現數據資源的互通和共享,提供工業建模所需的數據。通常需要成立專項數據治理組織,通過數據集成和定期運維等方式保證業務系統和線下數據準確與完整。此外,工業過程數據由于傳感器故障、人為操作因素、系統誤差、異構數據源、網絡傳輸亂序等因素極易出現噪聲、缺失值、數據不一致等情況,鑒于此通常需采用一定的數據預處理技術,消除數據中的噪聲、糾正數據不一致、識別和刪除離群數據,來提高算法模型的魯棒性,防止模型過擬合或欠擬合。
04 數據建模
對業務和數據進行深入理解,選擇合適的算法和建模工具,并對數據中的規律進行固化、提取,最后輸出數據分析模型。
工業模型不同于數據分析中的聚類、分類、回歸等算法,它更多的是基于業務機理知識與算法融合后解決實際業務問題的一套理論體系或業務機制。數據建模的本質是發現知識和固化知識,工業領域的知識主要通過試驗\試加工等手段獲得,把累次試驗加工所用到的參數慢慢地固化下來,最終得到穩定的產品質量,此邏輯對工業領域的數據建模同樣有效。
例如,我們在給航發某廠做外場服務備件年度需求預測分析時,首先定義業務場景及需求是面向服務部提供外場備件的需求預測服務,解決外場備件需求預測不準、不及時的問題。然后,通過數據集成和數據預處理等手段獲取外場備件預測相關的近十年發動機故障信息、裝機記錄、計量信息和發貨記錄等數據,在對數據進行充分理解和探索后,結合廠內業務專家的業務知識,在開展工業建模時將備件細分為換件頻次低但價值高的故障件(特殊消耗件、周轉件)和換件頻次高、換件量波動大且價值密度相對較低的消耗件(一般消耗件),分別進行建模預測。最后,在不同的規則約束下,通過模型評估和工程實際應用效果,優選出合適的算法模型,實現故障件和消耗件各自細分類別下的準確預測,極大提升了服務備件計劃的準確性和外場服務保障的及時性。
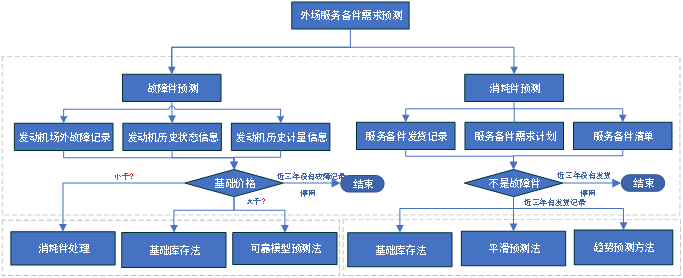
圖2:外場服務備件需求預測建模思路
因此,工業大數據建模需要對已有工業領域的知識深入理解,并在數據建模的過程中予以參考和融入,以通過數據分析獲得大量“不糾結于因果的知識”,這是得到高質量模型的關鍵所在。對于企業而言,鑒于場景化數據積累量和全面性短期難以全面達到全面數據分析的要求,可優先以挖掘到的新知識\方法相比現有業務環節在結果和流程上得到提升或改進為原則,以保證分析建模工作達到基礎的應用效果,然后在此基礎隨著數據積累和認知提升,持續改進優化。
05 模型的驗證和評估
確認數據分析的結果或模型是否滿足具體工業應用場景的使用需求的過程。
工業界通常追求分析結果具備高度的可靠性及準確性。所以,驗證與評估的重點是驗證模型在什么范圍內有效,有效程度是多少,不能只盯平均精度。也就是說,需要分場景去驗證和評估模型,結合數學精度要求與專業領域知識綜合進行評估和改善。例如,我們針對某鋼廠開展的硅鋼縱條紋工藝參數優化項目,通過領域知識發現硅和鋁的成分占比對生產工藝影響較大,但在工藝數據層面,此類關鍵參數控制的比較穩定,其對縱條紋影響的重要性就完全顯現不出來。因此,生產控制過程中涉及到的工藝參數優化,其目標應該是首先選擇波動較大的參數進行重點采集與調整,其次在設計區間約束的范圍內對模型進行控制與調整,開展實際生產驗證,進而獲得對生產控制策略改進優化后的模型。
06 模型部署
將訓練、分析得到的知識模型,以便于用戶使用的方式和要求重新固化,形成便于用戶使用的形式的過程,其成果可以是研究報告、可重復使用的數據挖掘程序或模型服務程序。
分析應用模型通常以軟件定義和呈現的方式應用在企業的業務、管理或者監控系統中。模型在運行過程中需要持續地進行優化,否則模型就沒有持續生命力,因為其精度很大程度上決定于數據的質量,往往模型在部署之后,由于缺乏數據的管理維護,導致數據的質量較差或者不滿足采集條件。因此,要保證分析模型給企業帶來效益,需要花費人力和物力保障數據的采集條件,從而為提高數據的精度奠定基礎。同時,隨著數據質量的提高和數量的增加,可能會挖掘出新的知識或規則,需要定期對模型進行完善,這也是推動模型不斷優化的動力。
結語
隨著工業大數據分析技術體系的不斷成熟、企業數據資產的不斷沉淀、應用場景的不斷延伸、數據化意識的不斷深化,工業大數據應用必將是企業數字化轉型的持續動力和重要著力點。未來,在新技術條件下,我們將同各類工業企業一起著力于實現貫穿于產品研發設計、生產、管理、倉儲、物流、服務等各業務環節和全流程的大數據采集、存儲、管理和分析應用,利用工業大數據分析技術和解決方案融合應用能力,挖掘工業數據的深層次價值,達到改進產品設計、提升生產效率、提高產品質量、降低企業成本、提升運營能力等多項目標,為提升企業的生產力、競爭力和創新力不斷賦能。





























 Tempo商業智能平臺
Tempo商業智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數據工廠平臺
Tempo數據工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數據治理平臺
Tempo數據治理平臺 Tempo主數據管理平臺
Tempo主數據管理平臺










 陜公網安備 61019002000171號
陜公網安備 61019002000171號



